- Cyclic
- Diverging
- Miscellaneous
- Perceptually Uniform Sequential
- Qualitative
- Sequential
- Sequential (2)plotting
Utility Functions that can be used to manage colors and other plotting tools. Includes all stable utility functions.
Work with color maps
plot_cmap_collections
plot_cmap_collections (cmap_collections:str|list[str]=None)
Plot all color maps in the collections passed as cmap_collections
| Type | Default | Details | |
|---|---|---|---|
| cmap_collections | str | list[str] | None | list of color map collections to display (from cmaps.keys()) |
The following color map collections are defined:
plot_cmap_collections will plot a color bar for each color map in the selected collections:
- A single collection
plot_cmap_collections('Cyclic')
- Several collections
plot_cmap_collections(['Qualitative', 'Sequential'])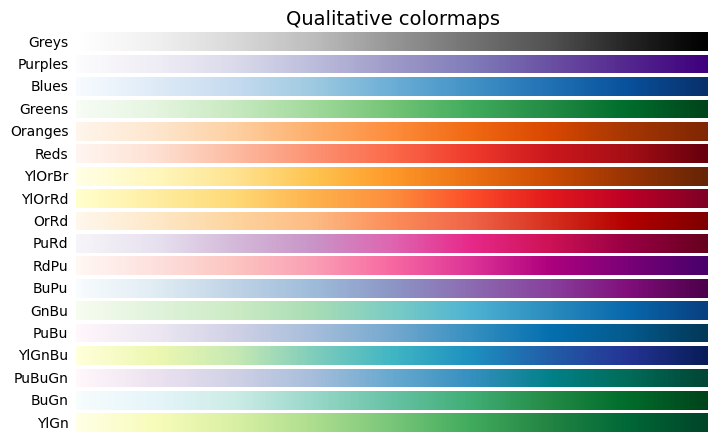
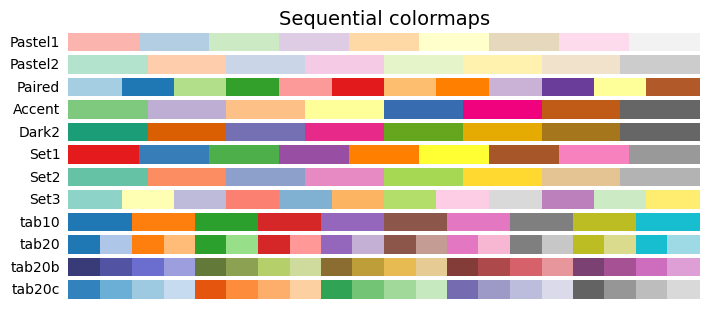
- All the collections
plot_cmap_collections()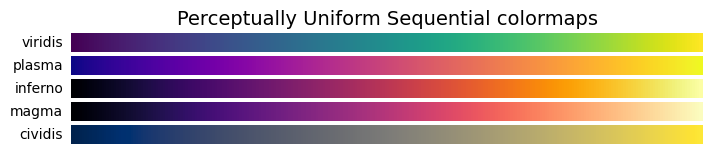

plot_color_bar
plot_color_bar (cmap:str, series:list[int|float]=None)
Plot a color bar with value overlay from series based on cmap
| Type | Default | Details | |
|---|---|---|---|
| cmap | str | string name of one of the cmaps | |
| series | list[int | float] | None | series of numerical values to show for each color |
plot_color_bar('tab10', range(10))
plot_color_bar('tab10', series=range(6))
plot_color_bar('tab10', series=[0, 1, 2])
get_color_mapper
get_color_mapper (series:list[int|float], cmap:str='tab10')
Return color mapper based on a color map and a series of values
| Type | Default | Details | |
|---|---|---|---|
| series | list[int | float] | series of values to map to colors | |
| cmap | str | tab10 | name of the cmap to use |
Usage
This function is used to ensure coherent colors for different plots.
- Define a color mapper based on values and cmap:
clr_mapper = get_color_mapper([1, 2, 3, 4], cmap='Paired) - Call the color mapper and have it return the appropriate values for any plot:
clr_mapper.to_rgba(2)
Example
We have dataset with several features.
import pandas as pd
from sklearn.cluster import DBSCAN, KMeans
from sklearn.datasets import make_blobsn_feats = 6
col_list = [f"col_{i}" for i in range(n_feats)]
X, y = make_blobs(n_samples=5_000, n_features=n_feats, centers=10, shuffle=True)
X = pd.DataFrame(X, columns=col_list)
X.head(3)| col_0 | col_1 | col_2 | col_3 | col_4 | col_5 | |
|---|---|---|---|---|---|---|
| 0 | -4.377115 | -3.113744 | 4.417737 | 7.327412 | 7.366114 | 0.033885 |
| 1 | -10.319655 | -6.998589 | 1.126784 | 7.731522 | 4.524063 | -1.337312 |
| 2 | 1.542669 | 6.398550 | 8.267037 | -1.024028 | -0.697208 | 8.599691 |
1. Define a color mapper based on values and cmap
We cluster the data into 10 clusters and make a scatter plot of two of the features, displaying the 10 cluster using a cmap.
To ensure that we can keep the same cluster color mapping for other plots, we use clr_mapper to predefine how colors are mapped to each cluster:
clr_mapper = get_color_mapper(cluster_ids, cmap=cmap).
clustering = KMeans(n_clusters=10)
clusters = clustering.fit_predict(X)
cluster_ids = np.unique(clusters)cmap='tab10'
plt.figure(figsize=(6, 3))
plt.scatter(X.col_0, X.col_1, c=clusters, s=2, cmap=cmap)
plt.colorbar()
plt.title('two first features data points, colored by cluster value')
plt.show()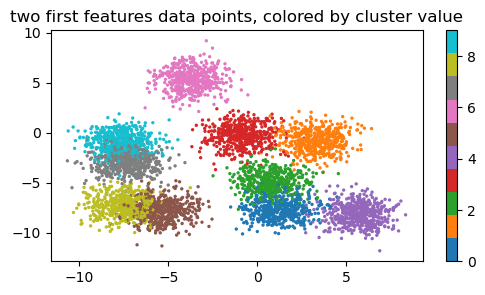
clr_mapper = get_color_mapper(cluster_ids, cmap=cmap)Call the color mapper and use it in any plot
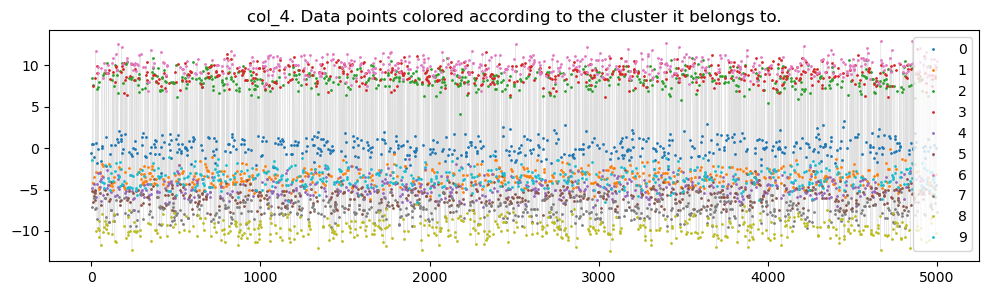
Use for another plot, showing another feature, and its value for each sample, colored according to its cluster
featname = 'col_4'
plt.figure(figsize=(12, 3))
plt.plot(X[featname], c='grey', alpha=.25, lw=0.25)
plt.title(f'{featname}.')
plt.show()
plt.figure(figsize=(12, 3))
plt.plot(X[featname], c='grey', alpha=.25, lw=0.25)
for c in cluster_ids:
mask = y == c
X[f"{featname}_{c}"] = X.loc[:, featname]
X.loc[~mask, f"{featname}_{c}"] = np.nan
plt.plot(X[f"{featname}_{c}"], label=str(c), c=clr_mapper.to_rgba(c), lw=0, marker='o', markersize=1)
plt.title(f'{featname}. Data points colored according to the cluster it belongs to.')
plt.legend()
plt.show()
Advanced plots
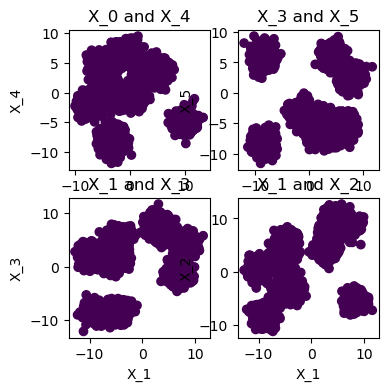
plot_feature_scatter
plot_feature_scatter (X:numpy.ndarray, y:Optional[numpy.ndarray]=None, n_plots:int=2, axes_per_row:int=3, axes_size:int=5)
Plots n_plots scatter plots of randomly selected combinations of two features out of X
| Type | Default | Details | |
|---|---|---|---|
| X | np.ndarray | input dataset. X.shape[1] is used to set the total number of features |
|
| y | Optional[np.ndarray] | None | target dataset |
| n_plots | int | 2 | number of feature pairs scatter plot to show |
| axes_per_row | int | 3 | number of axes per row. number of rows will be calculated accordingly |
| axes_size | int | 5 | size of one axes. figsize will be (ncols * axes_size, nrows * axes_size) |
X.shape(5000, 16)n_feats = 6
col_list = [f"col_{i}" for i in range(n_feats)]
X, y = make_blobs(n_samples=5_000, n_features=n_feats, centers=10, shuffle=True)
X = pd.DataFrame(X, columns=col_list)
plot_feature_scatter(X.values, y, n_plots=6, axes_per_row=3, axes_size=5)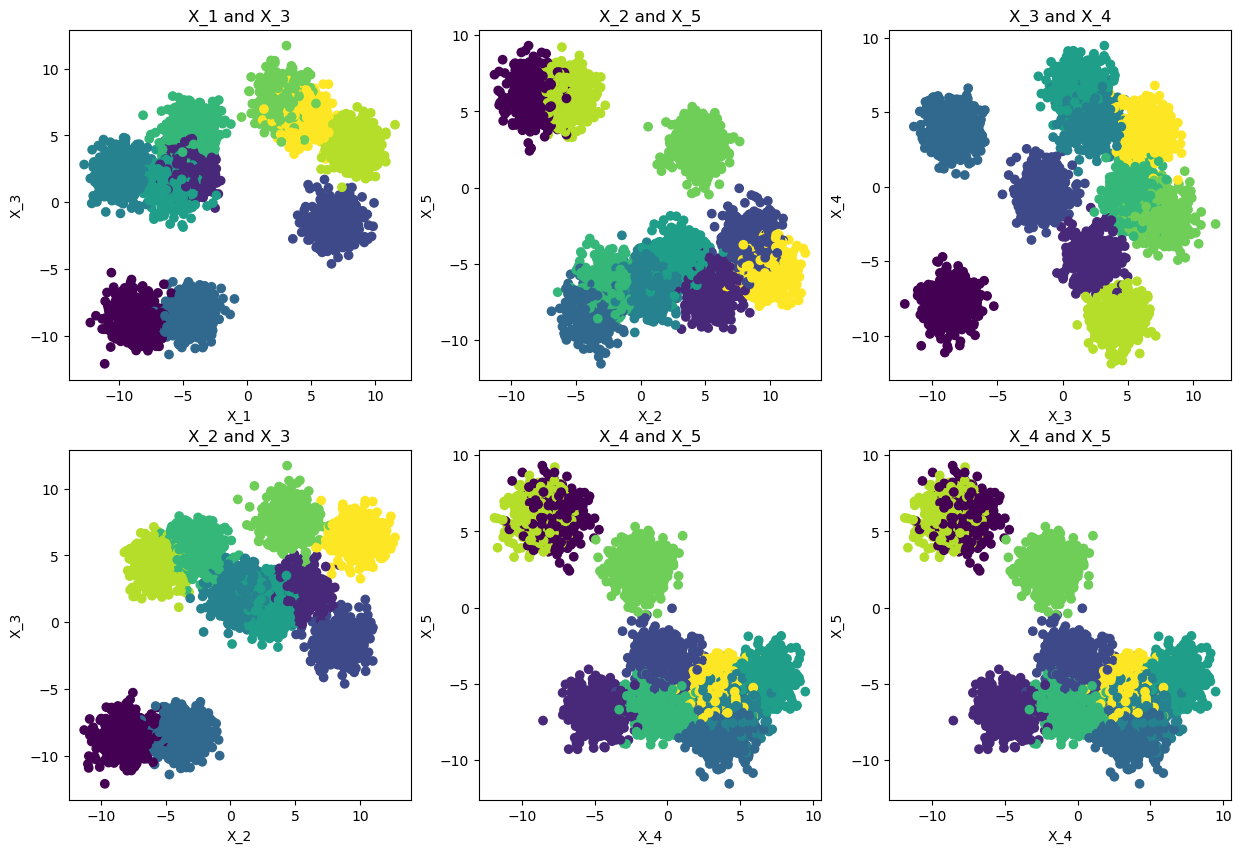
When not value is available for y, it is set to 1 by default
plot_feature_scatter(X.values, n_plots=4, axes_per_row=2, axes_size=2)